pandas-profilingが探索的データ解析にめちゃめちゃ便利だった件
当たり前の話だったら超恥ずかしいのですが、初めて知って驚愕したのでご紹介。
タイトルのとおり、pandas-profilingが探索的データ解析(EDA)にめちゃめちゃ便利だったのでご紹介するだけの記事です。
pandas-profilingの詳細はこちらからご確認を。 pandas-profiling
準備
pipやAnacondaを使うなどして、適宜ご自身の環境にインストール。
pip install pandas-profiling
あとはインポートするだけ。
import pandas as pd import pandas_profiling as pdp
実行
みんな大好きTitanicのtrainデータを使用。 なんの前処理もかけずに実行してみる。
df = pd.read_csv('train.csv')
pdp.ProfileReport(df)
Output
こんな感じでデータの全体像をHTMLで出力してくれます。便利。
画像
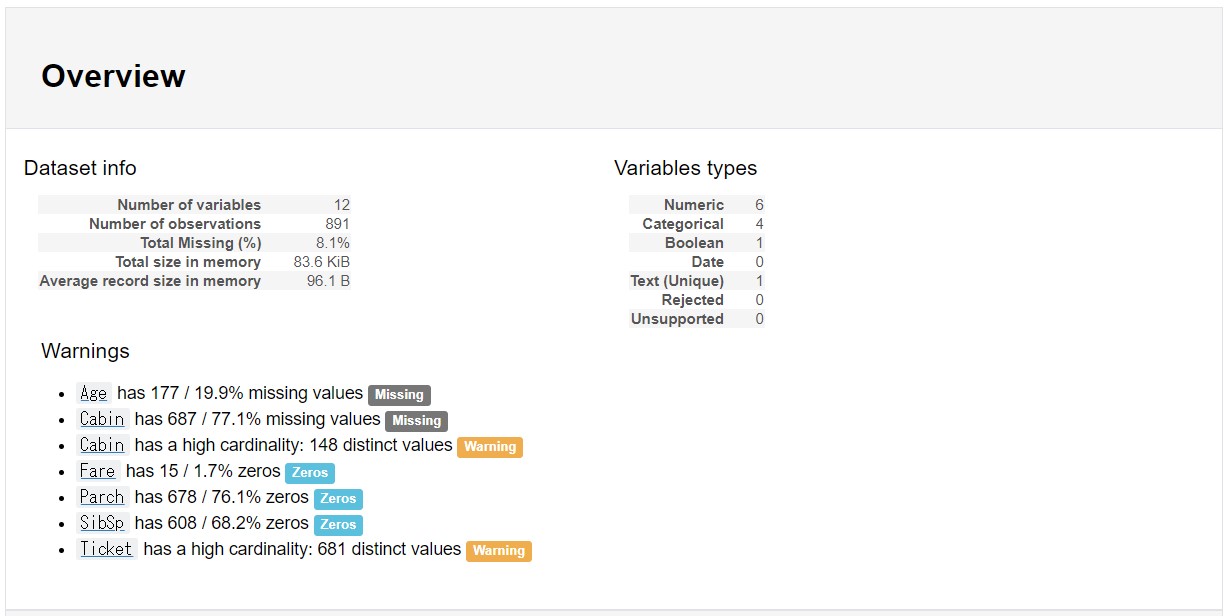

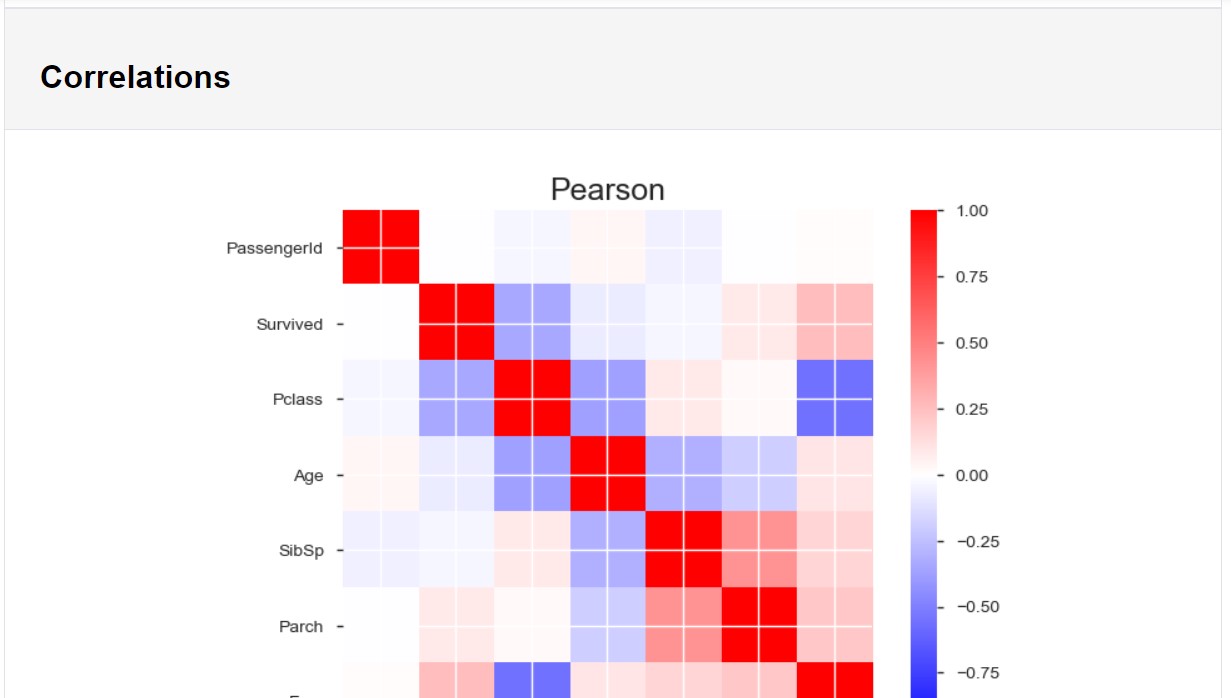
gif

データフレームの構造に、データ型別の基本統計量とグラフ、 数値データはピアソンの積率相関とスピアマンの順位相関といったところでしょうか。
膨大な説明変数があると大変そうですが、 1行のコードでここまで出してくれるのはEDAが捗りそうですねぇ。
また、以下でHTMLファイルの作成も可能。
profile = pdp.ProfileReport(df)
profile.to_file(outputfile="myoutputfile.html")
注意
Colaboratoryでやると表示、挙動が不安定でした。 Kaggle KernelはOK。
Colaboratoryでは何か方法があるかもしれません。 IT詳しい方、ご存知でしたら教えてください。
補足(2018/05/06追記)
プロフェッショナルの方がcolaboratory挙動の解決策記事を書いてくれています! HTMLファイルを生成して、埋め込む感じでうまくいくようです!
アイデアが形になる瞬間を刮目せよっ!インクストロークの再生
先日の記事を踏まえて、僕もWin10版アプリの機能をちょっと学ばないとと思っていたらこんなマークがリボンに。

再生?
なんのこっちゃ?埋め込みYoutubeとかのコンテンツでも再生する機能か?
と思って調べたらこんな感じでした。
Windows 10 の OneNote でのインク ストロークを再生する
ほう。
書いた順に再生される機能のようです。
これ、インクストロークだけじゃないようですね。

だから何だ感満載。
クリエイティブな人種の方が、
「おれのアイデアが形になる過程そんなにみたい?」
って場面があったら公式HPみたいになるのかな?
とりあえずタブレットで使わない派の自分には半世紀に一度も訪れないシチュエーションであろう。
【第3回】Python Marketing Data Analytics! ~集計と検定~
さて、前回に引き続き、今回は集計・検定を実施してデータの理解をさらに深めたいと思います~。 ただし、データが大きいので、検定はあくまで方法論だけって感じですね。
集計
集計は、可視化と並び、データの基本的な傾向を把握するために必須といっていいと思う。 集計した上で可視化するなども必要だ。
少し前処理を行えば、数値・カテゴリー、いずれの場合でも実施可能である。 さっそく実施してみよう。
まずはいつもどおり、headを確認するところから。
df.head(3)
| age | job | marital | education | default | balance | housing | loan | contact | day | month | duration | campaign | pdays | previous | poutcome | y | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 30 | unemployed | married | primary | no | 1787 | no | no | cellular | 19 | oct | 79 | 1 | -1 | 0 | unknown | no |
| 1 | 33 | services | married | secondary | no | 4789 | yes | yes | cellular | 11 | may | 220 | 1 | 339 | 4 | failure | no |
| 2 | 35 | management | single | tertiary | no | 1350 | yes | no | cellular | 16 | apr | 185 | 1 | 330 | 1 | failure | no |
グラフ化の際、yの構成は、noが大半を占めることがわかっている。
正確な件数を集計してみたい。
df['y'].value_counts()
no 4000
yes 521
Name: y, dtype: int64
その他、オブジェクトの変数の各項目別の集計値を確認する。
item = np.array(df.describe(include='O').columns) for i in item: print('【%(i)s】' %locals()) print(df[i].value_counts()) print('-'*30)
【job】
management 969
blue-collar 946
technician 768
admin. 478
services 417
retired 230
self-employed 183
entrepreneur 168
unemployed 128
housemaid 112
student 84
unknown 38
Name: job, dtype: int64
------------------------------
【marital】
married 2797
single 1196
divorced 528
Name: marital, dtype: int64
------------------------------
【education】
secondary 2306
tertiary 1350
primary 678
unknown 187
Name: education, dtype: int64
------------------------------
【default】
no 4445
yes 76
Name: default, dtype: int64
------------------------------
【housing】
yes 2559
no 1962
Name: housing, dtype: int64
------------------------------
【loan】
no 3830
yes 691
Name: loan, dtype: int64
------------------------------
【contact】
cellular 2896
unknown 1324
telephone 301
Name: contact, dtype: int64
------------------------------
【month】
may 1398
jul 706
aug 633
jun 531
nov 389
apr 293
feb 222
jan 148
oct 80
sep 52
mar 49
dec 20
Name: month, dtype: int64
------------------------------
【poutcome】
unknown 3705
failure 490
other 197
success 129
Name: poutcome, dtype: int64
------------------------------
【y】
no 4000
yes 521
Name: y, dtype: int64
------------------------------
比率でも確認してみる。
item = np.array(df.describe(include='O').columns) for i in item: print('【%(i)s】' %locals()) print(df[i].value_counts(normalize=True)) print('-'*30)
【job】
management 0.214333
blue-collar 0.209246
technician 0.169874
admin. 0.105729
services 0.092236
retired 0.050874
self-employed 0.040478
entrepreneur 0.037160
unemployed 0.028312
housemaid 0.024773
student 0.018580
unknown 0.008405
Name: job, dtype: float64
------------------------------
【marital】
married 0.618668
single 0.264543
divorced 0.116788
Name: marital, dtype: float64
------------------------------
【education】
secondary 0.510064
tertiary 0.298607
primary 0.149967
unknown 0.041363
Name: education, dtype: float64
------------------------------
【default】
no 0.98319
yes 0.01681
Name: default, dtype: float64
------------------------------
【housing】
yes 0.566025
no 0.433975
Name: housing, dtype: float64
------------------------------
【loan】
no 0.847158
yes 0.152842
Name: loan, dtype: float64
------------------------------
【contact】
cellular 0.640566
unknown 0.292856
telephone 0.066578
Name: contact, dtype: float64
------------------------------
【month】
may 0.309224
jul 0.156160
aug 0.140013
jun 0.117452
nov 0.086043
apr 0.064809
feb 0.049104
jan 0.032736
oct 0.017695
sep 0.011502
mar 0.010838
dec 0.004424
Name: month, dtype: float64
------------------------------
【poutcome】
unknown 0.819509
failure 0.108383
other 0.043574
success 0.028534
Name: poutcome, dtype: float64
------------------------------
【y】
no 0.88476
yes 0.11524
Name: y, dtype: float64
------------------------------
これでオブジェクトのデータの全体像も理解できた。
次はyと各変数の結果に関連が無いか確認してみたい。
例えば、定期預金の有無は生活の余裕や階級に深く影響していそうだ。
所得階級が高そうな層は定期預金契約者が多く、階級が低い場合は契約が少ないという傾向があるのではないか。
まずは対象者の仕事別に上記の仮説を検証しよう。
cross1 =pd.crosstab(df['y'], df['job'], margins=True, normalize='index') cross1
| job | admin. | blue-collar | entrepreneur | housemaid | management | retired | self-employed | services | student | technician | unemployed | unknown |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| y | ||||||||||||
| no | 0.105000 | 0.219250 | 0.038250 | 0.024500 | 0.209500 | 0.044000 | 0.040750 | 0.094750 | 0.016250 | 0.171250 | 0.028750 | 0.007750 |
| yes | 0.111324 | 0.132438 | 0.028791 | 0.026871 | 0.251440 | 0.103647 | 0.038388 | 0.072937 | 0.036468 | 0.159309 | 0.024952 | 0.013436 |
| All | 0.105729 | 0.209246 | 0.037160 | 0.024773 | 0.214333 | 0.050874 | 0.040478 | 0.092236 | 0.018580 | 0.169874 | 0.028312 | 0.008405 |
上記で、y別の仕事の構成比(横100%)が把握できる。
が、すこし分かりづらいのでヒートマップを使って加工すると、一目瞭然になる。
plt.figure(figsize=(18,5)) sns.heatmap(cross1, fmt="1.2f", annot=True, cmap="coolwarm") plt.show()

managementが仕事の人はyesの割合が多く、blue-collarが仕事の人はnoの割合が多い。
先の仮説はあながちまちがいではなさそうである。
その他の指標も確認してみたい。
item = np.array(df.describe(include='O').columns) for i in item: cross =pd.crosstab(df['y'], df[i], margins=True, normalize='index') plt.figure(figsize=(15,5)) sns.heatmap(cross, fmt="1.2f", annot=True, cmap="coolwarm") plt.show()










このように、クロス集計を行うことにより、各要因での差を比較することが可能になる。
しかし、クロス集計のみでデータ分析を行い、結論づけることは危険だ。
- 2変数間の比較しかできず、その背後にありうる他の変数の影響を把握できない
- 生じた差が偶然発生したものか判断できない
まず上の論点は、説明変数が別の説明変数の影響を受けている状況を加味できないである。
これが拡張すると、単なる疑似相関の結果を、「相関がある」と誤った結論を導き出してしまうリスクがある。
このため、疑似相関を疑う事前の仮説設計や、多変量解析が重要になる。
疑似相関については以下wikiを参照しただくと良い。
疑似相関
次の論点は、データがビッグデータと呼ばれるほど膨大ではない場合、
生じた差は、説明変数が影響しているのではなく単なるサンプリングの誤差なのではないか?という問いである。
この問いに応える一つの手法が、統計学的検定である。
検定
統計学的検定の理論的な内容は以下を参照いただくとよい。
さっそく、各変数と目的変数yの集計結果について、有意水準0.05で検定を行ってみる。
item = np.array(df.describe(include='O').columns) for i in item: chisq =pd.crosstab(df['y'], df[i], margins=False) chi, p, d, expect = sp.stats.chi2_contingency(chisq) print('【%(i)s】' %locals()) print("p_values : %(p)s" %locals() ) if p < 0.05: print("★有意差あり") else: print("有意差なし") print('-'*30)
【job】
p_values : 1.901391096662705e-10
★有意差あり
------------------------------
【marital】
p_values : 7.373535401823763e-05
★有意差あり
------------------------------
【education】
p_values : 0.001625240003630989
★有意差あり
------------------------------
【default】
p_values : 0.9254599873026758
有意差なし
------------------------------
【housing】
p_values : 2.7146998959323014e-12
★有意差あり
------------------------------
【loan】
p_values : 2.9148288298428256e-06
★有意差あり
------------------------------
【contact】
p_values : 8.30430129641147e-20
★有意差あり
------------------------------
【month】
p_values : 2.195354833570811e-47
★有意差あり
------------------------------
【poutcome】
p_values : 1.5398831095860172e-83
★有意差あり
------------------------------
【y】
p_values : 0.0
★有意差あり
------------------------------
すべて実施すると分かるとおり、default意外はすべてp値が0.05以下、有意差ありと判断されている。
これは検定の性質によるもので、データの量が大きくなるほどp値は低くなる傾向がある。
今回のように5,000弱のデータであると、ほんの少しの差も有意差として判断されてしまう。
ビッグデータ時代の昨今では、あまり統計学的検定の意義は以前よりも少なくなっているのかもしれない。
補足
少し話が脇道にそれるが、数値データを区分し、カテゴリカルデータとして処理することもできる。
df_dummies = df df_dummies['age_categorical'] = 0 df_dummies.loc[df_dummies['age'] <= 20, 'age_categorical' ] = '-20' df_dummies.loc[(df_dummies['age'] > 20 ) & ( df_dummies['age'] <= 40 ), 'age_categorical'] = '21-40' df_dummies.loc[(df_dummies['age'] > 40 ) & ( df_dummies['age'] <= 60 ), 'age_categorical'] = '41-60' df_dummies.loc[df_dummies['age'] >60, 'age_categorical' ] = '60-' df_dummies['age_categorical'].value_counts()
21-40 2425
41-60 1962
60- 127
-20 7
Name: age_categorical, dtype: int64
cross =pd.crosstab(df_dummies['age_categorical'], df_dummies['y'], margins=True, normalize='index') plt.figure(figsize=(10,5)) sns.heatmap(cross, fmt="1.2f", annot=True, cmap="coolwarm") plt.show()

連続的な数値データをカテゴリ化するのは構成比が分かりやすい反面、情報量が削減されるため、 ケースバイケースで判断することとなる。
おわりに
‘pandas‘を使うと集計も楽勝ですね~。 ただ、ここまで紹介したのはあくまで2変数の関係性の話。 おそらく目的変数は多変数の影響を受けていると考えられるので、 今後は多変量解析を焦点にしたいと思いますー。 あ、その前にダミー変数化とか前処理をいれるかも。
とりあえずまたGWに書き溜め&勉強します。
OneNote信者なら、タスク管理にPlannerやOutlook、Trello、Googleなんて使わないよねっ
いつもお世話になっているやまさんが、先日こんな書き込みしていたので、今日のネタはこれっ!
普段の打ち合わせはPC持ってるコトが多いので、伝えるべきコト、確認すべきコト等をOne Note の「タスクノートシール」(チェックリスト作れるヤツ)でガーっと箇条書きして挑むようにしてます。※喋り過ぎてしまうタイプだと自覚があるので(汗 > RT
— やま (@yamad365) 2018年4月19日
ノートシールの話です~。

タスクリストが作れるんだぜ。
主に、タスクや、重要事項などのラベルを付けたいときに便利な機能がノートシール。
読んで字のごとく、以下のようなノートシールを選択すると、文章などがラベリングできる機能です。

いろんなリストから選択してラベリングしてみよう!

検索性、最強
たぶん最も使うのはタスクを管理できる「タスクノートシール」。 チェックボックスとして機能します。
また、いろいろなブックにまたがるタスクを含めたノートシール一式も一瞬で検索してくれる。

すごい!
さらに、ノートシールを集めて、各ページへのリンク付きの概要ページを作成する機能も!

便利!
みんな使おう!
タイトルに書いたOutlookタスクですが、OneNote上で共有できるから、 Outlookタスク使っている人は実は便利。
Plannerは使ったことないからよくわからない。
Trelloは良ツール。
ちなみに僕はGoogleタスク愛用者で・・・・おっと、だれか来たようだ。
【第2回】Python Marketing Data Analytics! ~データ確認の第一歩、可視化~
さて、前回に引き続き、銀行のキャンペーンマーケティングデータに基づく分析をネタにした勉強記録ですー。
データの可視化
まずは、データのheadを確認。
df.head()
| age | job | marital | education | default | balance | housing | loan | contact | day | month | duration | campaign | pdays | previous | poutcome | y | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 30 | unemployed | married | primary | no | 1787 | no | no | cellular | 19 | oct | 79 | 1 | -1 | 0 | unknown | no |
| 1 | 33 | services | married | secondary | no | 4789 | yes | yes | cellular | 11 | may | 220 | 1 | 339 | 4 | failure | no |
| 2 | 35 | management | single | tertiary | no | 1350 | yes | no | cellular | 16 | apr | 185 | 1 | 330 | 1 | failure | no |
| 3 | 30 | management | married | tertiary | no | 1476 | yes | yes | unknown | 3 | jun | 199 | 4 | -1 | 0 | unknown | no |
| 4 | 59 | blue-collar | married | secondary | no | 0 | yes | no | unknown | 5 | may | 226 | 1 | -1 | 0 | unknown | no |
実際にデータの内容を把握するため、グラフとして可視化してみることからスタートする。
まずは、分析したい対象に着目することがデータ分析の第一歩となる。
今回は、「y(定期預金の契約有無)」が対象だ。
このデータがどのような特性があるのか、このデータに影響を与えている変数はあるのか、
などを仮説を立てながら可視化し、検証していく。
sns.countplot(x='y', data=df)

データの大部分はnoの結果であることが分かる。
具体的な数値は集計時に確認してみる。
yesとnoの結果の違いは何からもたらされるのだろうか?
例えば、前回キャンペーンの効果結果は、今回のキャンペーンの結果による定期預金申込有無に効果を示しそうである。
sns.countplot(x='poutcome', hue='y', data=df)

データをみると、確かに前回結果がsuccessの群は、目的変数がyesとなっている人が多いことが分かる。
ただ、カテゴリごとのデータのサイズが大きく異なるため、単純なcountplotだけだと見にくいようだ。
これは、集計により比率等を算出してクロス集計を行ったり、
目的変数をダミー変数化して、数値データとして扱うことで、傾向を分かりやすく表現するなどの工夫が必要そうである。
カテゴリーデータ毎の可視化は、何らかの集計や加工をして可視化したほうが良さそうだ。
特に目的変数(今回でいえばy)が2値データの場合、ロジット関数をリンク関数としたモデル、
いわゆるロジスティック回帰モデルでモデリングしてみることが発生すると思われるので、ダミー変数化はほぼ必須である。
ダミー変数化とそれに伴う可視化・モデリング等はまた別の回で取り組んでみたい。
次に、数値データとカテゴリーデータの可視化はどうだろう?
まず気になるのは、ageとyの関係である。
age(年齢)は様々なデータ分析の説明変数になりやすい重要な要素である。
ageの分布をヒストグラムで可視化してみる。
plt.figure(figsize=(5,5)) plt.hist(df.age, bins=30) plt.show()

30歳代~40歳代が最もデータ数が多いようである。
60歳代以降になると人数は急激に減少する。
では次に、ageとyとの関係を確認しよう。
yの結果ごとにみた場合、ageの分布の傾向に特性がみられるかが焦点になる。
以下のとおりグラフを重ねて表示してみる。
age_y = df[df['y'] == 'yes']['age'] age_n = df[df['y'] == 'no']['age'] plt.figure(figsize=(5,5)) plt.hist(age_y, bins=30, alpha=0.5, color='cornflowerblue', label='$y=yes$') plt.hist(age_n, bins=30, alpha=0.5, color='mediumseagreen', label='$y=no$') plt.legend() plt.show()

y = no のサイズが大きいため、ヒストグラム自体を重ねると、分布の違いは比較できないようだ。 そこで、グラフを2つに分けて比較してみる。
fig, gr = plt.subplots(1,2,figsize=(12,5)) gr[0].hist(age_y, bins=30, color='cornflowerblue') gr[0].set_title('$y=yes$') gr[0].set_xlabel=('age') gr[1].hist(age_n, bins=30, color='mediumseagreen') gr[1].set_title('$y=no$') gr[1].set_xlabel=('age') plt.show()

y = yes の群のほうが、やや高齢層の比率が高いように思える。
年齢が高いほど yes の可能性が高くなるかどうかは、今後の検討材料になりそうだ。
データの分布は、もう少し分かりやすく描写する方法もある。
plt.figure(figsize=(8,5)) sns.distplot(df['age'], bins=30, color='cornflowerblue') plt.show()

上記のグラフは、カーネル密度推定を行ったグラフである。
データから推定した確率密度関数を描写しており、データの背後にあると想定される確率分布が可視化できる。
カーネル密度推定については、以下wikiを参照するとよい。
カーネル密度推定
これを使えば、異なるカテゴリの分布の違いが比較的分かりやすく描写できる。
fig = sns.FacetGrid(df, hue='y', aspect=4) fig.map(sns.kdeplot, 'age', shade=True) fig.add_legend() plt.show()

上記のとおり、yes、noの群では、若年層と高齢層で差がみられる。
yesの群のほうが分散が大きいようである。
各変数間のデータの状況を知りたいときは、sns.pairplotを利用すると便利だ。
データフレームの数値データだけになるが、それぞれの散布図行列図を出力できる。
回帰直線も描写されるため、相関関係も(なんとなく)把握できる。
sns.pairplot(df, hue="y", size=2, kind='reg', diag_kind='kde') plt.show()

グラフだけみると、balanceとageの関係について、y = yesの群では正の相関がありそうな描写となっている。
これを確かめるため、この変数だけにしぼって描写してみる。
sns.jointplot('balance','age', df[df['y']=='yes'], kind="reg") plt.show()

このデータをみると、ageとbalanceの間に相関関係はほとんどみられないことが分かる。
単に見た目の問題ではなく、きちんと数値で確認することが重要なようだ。
データセットを構成する変数同士の相関(連関)が、後々回帰分析を行う際のマルチコ(多重共線性)の有無を把握する際に重要になることがある。
変数同士の相関については、相関行列図を描写することが最も相関関係が分かりやすいため、どこかで実施していくことが必須になる。
なお、相関=因果ではないことは特に気を付けて分析してくべきだ。 疑似相関の問題も常に念頭に入れておくと良いと思う。
次に、前回に少し着目したbalanceの分布についてもう少し詳細に確認してみることにする。
まずはKDEプロットを行う。
fig = sns.FacetGrid(df, hue='y', aspect=5) fig.map(sns.kdeplot, 'balance', shade=True) fig.add_legend() plt.show()

記述統計の際に推察したとおり、右裾がとても長い分布になっているようである。
分布の形状に関しては、ヴァイオリンプロットと呼ばれるグラフも分かりやすい。
sns.factorplot(x='y', y='balance', data=df, kind='violin',aspect=2) plt.show()

balanceは裾が長い分布であるのでかなり分かりづらいかもしれないが、
ageを例にもう一度描写してみると、分布についてよく分かる。
sns.factorplot(x='y', y='age', data=df, kind='violin',aspect=2) plt.show()

バイオリンプロットは、3変数の分布も大変分かりやすく描写してくれる。
以下は、「婚姻状況(marital)」、「年齢(age)」、「定期預金契約(y)」の分布。
ax = sns.violinplot(x="marital", y="age", hue="y",aspect=.5, data=df, split=True) plt.show()

単身者は低年齢、婚姻・離婚者は中央値はやはり高く、分散も大きい。
また、高齢の定期預金契約者が多いのはmarriedとdivorcedが顕著である。
今後の解析において、データが正規分布に基づいているか確認することが必要になるケースがある。
balanceとageの正規性を確認してみたい。
plt.figure(figsize=(5,5)) gr = stats.probplot(df['age'], plot=plt) plt.title('age') plt.show()

plt.figure(figsize=(5,5)) gr = stats.probplot(df['balance'], plot=plt) plt.title('balance') plt.show()

上記グラフはQ-Qプロットと呼ばれる。
観測値がある確率分布に従う場合の期待値と観測値のデータを2次元に表示したものだ。
今回は正規分布を理論分布と仮定しているため、正規Q-Qプロットなどと呼ばれる。
データの青いプロットが、赤いラインに沿えばこのデータが正規分布に従っていると判断できる。
しかし、age,balanceのいずれも両側が上向きに歪んでおり、正規分布以上に裾が広がっていると考えられる。
正規性を仮定した分析は好ましくないようだ。
直観的な解釈ではなく、客観的に検定を行う手法もある。
Shapiro-Wilk検定やKolmogorov-Smirnov検定がそれにあたる。
ただし、昨今はビッグデータとよばれる大量データを分析することが多いようであるため、検定を行うシチュエーションは減っているようである。
(サンプルサイズが大きいほど、p値が小さくなるため)
stats.shapiro(df['age'])
(0.9595122933387756, 9.410944406190885e-34)
stats.shapiro(df['balance'])
(0.5015109777450562, 0.0)
いずれもp値は0.05を下回るため、帰無仮説(データは正規分布に従う)は棄却される。
つまり、両データとも正規性を有しないデータであることが分かる。
ただし、本データはサイズが大きく、P値が優位になりやすいため、検定は適切ではなさそうではあるが、
ひとつのテクニックとして覚えておくと良さそうだ。
終わりに
ここまで書いた後でしたが、欠損値補完を完全に飛ばしてたー。
まぁ、どこかの段階でやりましょう。
Pythonだと限界があるので、Rを呼び出してみる必要性があるかも。
とりあえず、このまま進めちゃえってことで、次はクロス集計と検定をやりまーす。
上半期最大の衝撃。OneNote、Win10付属版が主軸に?!
最近、世間をこのようなニュースが騒がせています。
…え?知らない?そんなご冗談をw
つまり、OfficeファミリーのOneNoteは2016で終了。 今後はWindows10付属版が主軸になるようです。
「何を言っているんだお前は・・・?」
という方。 ぜひ以下を確認いただきたい。
貴方がWin10ユーザーで、office365が入っていれば、 以下2つのOneNoteがPCにインストールされているはずです。

上がWin10付属OneNote。 下がOffice OneNote2016。
それぞれUIも大きく異なる。
Win10付属OneNote

Office OneNote2016

皆さまはどっち派だろうか?僕は残念ながらOffice派。
動揺を隠しえません。 願わくば、UIをDesktop版並みにしてほしいものです・・・。
【第1回】Python Marketing Data Analytics! ~古典的マーケティングデータ分析にも目を向けて~

このカテゴリは本業、データ分析系のお話やTipsです。
Qiitaに書くレベルではない自分の覚書や練習記録、情報提供として残していこうかと。
1年後に「まだ自分はこの程度だったのか~wクソダサいww」というのが目標です。
つーかブログ趣旨とギャップありすぎて、別ブログ立ち上げるべきかと思いましたが、
まあゆるくやっていけばいいや、というめんどくさい精神全開の結果です。ご容赦ください。
モチベーション
なんでこんなタイトルにしたかというと、
機械学習・ディープラーニングが全盛の中、もうちょっとPythonでの古典的な統計解析、データ分析手法中心のネタがあってもいいんじゃね?
と思ったから。
というか、僕自身が勉強しないと、基礎が全くダメだなぁと思ったからです。
Pythonで機械学習・ディープラーニングによる予測精度向上が全盛だけど、ScipyやStatsmodelsを中心に、モデル推定や効果検証とかも勉強しないとだめだなぁ。
— H.Kobayashi (@h_kobayashi1125) 2018年4月17日
まぁ、Python自体が統計解析ライブラリがRほど充実していないので、当然といれば当然ですが・・・。
ビッグデータと呼ばれる大量データの分析が中心の今、データ分析は推測統計や検定はだいぶ意気消沈していそうな気がします。
(機械学習系の情報がWebに溢れかえっているせいかもしれませんが・・・)
でも世間にはきっと、
データは少ないけど、そこから得られるものを導き出したい。
予測ではなくて、目的変数に与える影響要因の分析がしたい。
とか、そういうニーズも多いはず。
いわゆるAIでの予測ではなく、BI(ビジネスインテリジェンス)の視点でデータからインサイトを得よう!という趣旨のデータ分析ですね。
ということで、勉強がてら、「マーケティング」をネタにしたPythonデータ分析記事を色々書いていこうと思います。
もちろん、機械学習の技術なども入ってくると思いますが。
なお、内容には誤りなどがある可能性がありますので、ご容赦ください。
ぼくの勉強不足&不手際です。精進します。
お気づきの際はご指摘いただけると喜びます。
実行環境について
以下の記事を参照ください。
Kaggleのデータは使わないと思いますが、Colaboratory(Python3)を使ってます。
利用データについて
しばらくは、UCI Machine Learning RepositoryのBank Marketing Data Set を利用していきます。
利用するデータはbank.csvです。
では、以下からスタート!長く続くといいなぁw
必要ライブラリのインポート
import numpy as np import pandas as pd from scipy import stats import matplotlib.pyplot as plt import seaborn as sns %matplotlib inline
データの読み込み
pd.set_option("display.max_columns", 50) df = pd.read_table('bank.csv', sep=';') df.head()
| age | job | marital | education | default | balance | housing | loan | contact | day | month | duration | campaign | pdays | previous | poutcome | y | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 30 | unemployed | married | primary | no | 1787 | no | no | cellular | 19 | oct | 79 | 1 | -1 | 0 | unknown | no |
| 1 | 33 | services | married | secondary | no | 4789 | yes | yes | cellular | 11 | may | 220 | 1 | 339 | 4 | failure | no |
| 2 | 35 | management | single | tertiary | no | 1350 | yes | no | cellular | 16 | apr | 185 | 1 | 330 | 1 | failure | no |
| 3 | 30 | management | married | tertiary | no | 1476 | yes | yes | unknown | 3 | jun | 199 | 4 | -1 | 0 | unknown | no |
| 4 | 59 | blue-collar | married | secondary | no | 0 | yes | no | unknown | 5 | may | 226 | 1 | -1 | 0 | unknown | no |
データの概要を把握する
データ分析の第1歩は、そのデータの概要を掌握することからスタートしよう。
とくに、データに対するドメイン知識が無い場合、単なる記述統計からでもデータの背景にある事象の概況は推察できる。
df.shape
(4521, 17)
このデータは、4,521レコード、17カラムで構成されていることが分かる。
つまり、4,521人分のデータであり、1人あたり17の変数となるデータを持っていることになる。
df.columns
Index(['age', 'job', 'marital', 'education', 'default', 'balance', 'housing',
'loan', 'contact', 'day', 'month', 'duration', 'campaign', 'pdays',
'previous', 'poutcome', 'y'],
dtype='object')
各カラムの名前は上記コードで取得できる。 このデータセットは、ポルトガルの銀行機関のダイレクトマーケティングの実績データのようだ。
このデータセットを持ってきたUCI Machine Learning Repositoryから、データセットの変数の内容を拝借すると、以下のとおりとなっている。
| 変数名 | 内容 |
|---|---|
| age | 年齢 |
| job | 仕事 |
| marital | 婚姻有無 |
| education | 教育水準 |
| default | クレジットカードの債務不履行有無 |
| balance | 年間平均残高(€) |
| housing | j住宅ローンの有無 |
| loan | 個人ローンの有無 |
| contact | 連絡方法 |
| day | 最終接触日 |
| month | 最終接触月 |
| duration | 最終接触時間(秒) |
| campaign | キャンペーン中の連絡数 |
| pdays | 最後に連絡した日からの日数 |
| previous | キャンペーンまでに接触した回数 |
| poutcome | 以前のマーケティングキャンペーンの結果 |
| y | 定期預金の契約有無 |
※ちなみに、このデータを題材にSIGNEATEでオープンコンペが開かれている。
まず、それぞれのカラムとデータ型を確認する。
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 4521 entries, 0 to 4520
Data columns (total 17 columns):
age 4521 non-null int64
job 4521 non-null object
marital 4521 non-null object
education 4521 non-null object
default 4521 non-null object
balance 4521 non-null int64
housing 4521 non-null object
loan 4521 non-null object
contact 4521 non-null object
day 4521 non-null int64
month 4521 non-null object
duration 4521 non-null int64
campaign 4521 non-null int64
pdays 4521 non-null int64
previous 4521 non-null int64
poutcome 4521 non-null object
y 4521 non-null object
dtypes: int64(7), object(10)
memory usage: 600.5+ KB
int64の数値型が7カラム、objectが10カラムあることが分かる。 次に、各カラムの基本統計量を確認する。
df.describe()
| age | balance | day | duration | campaign | pdays | previous | |
|---|---|---|---|---|---|---|---|
| count | 4521.000000 | 4521.000000 | 4521.000000 | 4521.000000 | 4521.000000 | 4521.000000 | 4521.000000 |
| mean | 41.170095 | 1422.657819 | 15.915284 | 263.961292 | 2.793630 | 39.766645 | 0.542579 |
| std | 10.576211 | 3009.638142 | 8.247667 | 259.856633 | 3.109807 | 100.121124 | 1.693562 |
| min | 19.000000 | -3313.000000 | 1.000000 | 4.000000 | 1.000000 | -1.000000 | 0.000000 |
| 25% | 33.000000 | 69.000000 | 9.000000 | 104.000000 | 1.000000 | -1.000000 | 0.000000 |
| 50% | 39.000000 | 444.000000 | 16.000000 | 185.000000 | 2.000000 | -1.000000 | 0.000000 |
| 75% | 49.000000 | 1480.000000 | 21.000000 | 329.000000 | 3.000000 | -1.000000 | 0.000000 |
| max | 87.000000 | 71188.000000 | 31.000000 | 3025.000000 | 50.000000 | 871.000000 | 25.000000 |
まずは数値型のデータ確認。それぞれの用語は以下のとおりである。
| 項目 | 意味 |
|---|---|
| count | データ数 |
| mean | 算術平均 |
| std | 標準偏差 |
| min | 最小値 |
| 25% | 25パーセンタイル |
| 50% | 50パーセンタイル(中央値) |
| 75% | 75パーセンタイル |
| max | 最大値 |
オブジェクトのカラムの概要も以下で算出できる。
df.describe(include='O') # 大文字の「O(オー)」(Object)をincludeで指定すればオブジェクトのカラムを取得できる。
| job | marital | education | default | housing | loan | contact | month | poutcome | y | |
|---|---|---|---|---|---|---|---|---|---|---|
| count | 4521 | 4521 | 4521 | 4521 | 4521 | 4521 | 4521 | 4521 | 4521 | 4521 |
| unique | 12 | 3 | 4 | 2 | 2 | 2 | 3 | 12 | 4 | 2 |
| top | management | married | secondary | no | yes | no | cellular | may | unknown | no |
| freq | 969 | 2797 | 2306 | 4445 | 2559 | 3830 | 2896 | 1398 | 3705 | 4000 |
それぞれ用語は以下のとおり。
| 項目 | 意味 |
|---|---|
| count | データ数 |
| unique | 変数の種類数 |
| top | 最頻値 |
| freq | 最頻値の頻度 |
pandas.DataFrame.describeだけでもいろいろなことが分かりそうだ。
例えばbalanceに着目してみると、平均値と中央値(50%値)の値が大きく乖離しており、 平均値 > 中央値 となっている。
これは例えば年収分布と同じ減少で、少数の値が大きいデータやはずれ値に平均値が引き上げられている可能性を示す。
つまり、右に裾が長い分布となっていることが推察できる。
なお、pandas.DataFrame.describeでは数値、オブジェクトすべて一括して表示することも可能である。
df.describe(include='all')
| age | job | marital | education | default | balance | housing | loan | contact | day | month | duration | campaign | pdays | previous | poutcome | y | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 4521.000000 | 4521 | 4521 | 4521 | 4521 | 4521.000000 | 4521 | 4521 | 4521 | 4521.000000 | 4521 | 4521.000000 | 4521.000000 | 4521.000000 | 4521.000000 | 4521 | 4521 |
| unique | NaN | 12 | 3 | 4 | 2 | NaN | 2 | 2 | 3 | NaN | 12 | NaN | NaN | NaN | NaN | 4 | 2 |
| top | NaN | management | married | secondary | no | NaN | yes | no | cellular | NaN | may | NaN | NaN | NaN | NaN | unknown | no |
| freq | NaN | 969 | 2797 | 2306 | 4445 | NaN | 2559 | 3830 | 2896 | NaN | 1398 | NaN | NaN | NaN | NaN | 3705 | 4000 |
| mean | 41.170095 | NaN | NaN | NaN | NaN | 1422.657819 | NaN | NaN | NaN | 15.915284 | NaN | 263.961292 | 2.793630 | 39.766645 | 0.542579 | NaN | NaN |
| std | 10.576211 | NaN | NaN | NaN | NaN | 3009.638142 | NaN | NaN | NaN | 8.247667 | NaN | 259.856633 | 3.109807 | 100.121124 | 1.693562 | NaN | NaN |
| min | 19.000000 | NaN | NaN | NaN | NaN | -3313.000000 | NaN | NaN | NaN | 1.000000 | NaN | 4.000000 | 1.000000 | -1.000000 | 0.000000 | NaN | NaN |
| 25% | 33.000000 | NaN | NaN | NaN | NaN | 69.000000 | NaN | NaN | NaN | 9.000000 | NaN | 104.000000 | 1.000000 | -1.000000 | 0.000000 | NaN | NaN |
| 50% | 39.000000 | NaN | NaN | NaN | NaN | 444.000000 | NaN | NaN | NaN | 16.000000 | NaN | 185.000000 | 2.000000 | -1.000000 | 0.000000 | NaN | NaN |
| 75% | 49.000000 | NaN | NaN | NaN | NaN | 1480.000000 | NaN | NaN | NaN | 21.000000 | NaN | 329.000000 | 3.000000 | -1.000000 | 0.000000 | NaN | NaN |
| max | 87.000000 | NaN | NaN | NaN | NaN | 71188.000000 | NaN | NaN | NaN | 31.000000 | NaN | 3025.000000 | 50.000000 | 871.000000 | 25.000000 | NaN | NaN |
このような記述統計からデータの概要を把握していくことが第一歩となる。
つぎに、推察した内容が的確かどうか、データの可視化などを進めて確認していく。
つづく
とりあえず今回はここまで。 次回はmatplotlibやseabornを使ってデータの可視化を行っていきます。
考察
Colaboratory上の.ipynbを.mdにしてブログに上げるのがクソめんどくさいことが分かったので、
今後どうするか模索。
普通にjupyterでやるべきなのか・・・。GitHubを使うのも良さそう。