OneNoteにねじ込めるコンテンツあれこれ
久々にエントリ投下。
OneNote埋め込みコンテンツ特集~(`・ω・´)
Youtube
Youtube見たことない人はいないですね。
動画URLをOneNote上にコピペすると、コンテンツとして埋め込むことができます。

SlideShare
パワポ等プレゼンテーションのスライドを共有・公開できるサイト。
こちらもURLコピペです~。

Sway
皆さんSway知ってます?よね?
オンライン上でプレゼンのスライドや自己紹介のストーリーを作れるツールです。

PowerBI レポート
まぁコレが言いたかっただけなんですがw
PowerBIレポート(パブリック)を埋め込むことができます!

PowerBIユーザーとしては紹介しないわけにはいきませんな。
良いOneNote&BIライフを!!!
その他埋め込めるサイト
こちら以外にも、いろいろなコンテンツが埋め込めるようになっています。
公式に詳しい内容が記載されていますね。
埋め込めるからなんだって話もあるのですが、 そこは利用者の力の見せ所といったところでしょう。
OneNoteは数学嫌いな人をこの世から一掃するつもりらしい。
こちらの記事で、OneNoteのWin10アプリが主軸にということを伝えていたところです。
個人的にはOffice版が好きなんですが、
アプリ版でぶっとんだ機能が追加されています。
数式からグラフを生成する
これ、楽しすぎて寝不足になりました(笑)

自分の手書き数式が、テキストだけじゃなくてグラフにもなっちゃうという。
さらに、パラメーターまで編集できるという。
関数嫌いが出てくる中学生くらいの時にこれがあれば、みんな楽しかっただろうなぁ。
円の方程式ももちろんグラフになる。

※ちょっと複雑な確率密度関数とかはさすがにダメでした。今後に期待。
テストのカンニングにばっちりだね!
方程式に含まれる変数ごとの解法まで確認できるというぶっとんだ機能つき。

グラフに切片やら極小・極大の数値つき。
関数に悩める中学生・高校生のみなさん、ぜひテスト会場にOneNote Win10をお忘れなくっ!
Excelから大量のOneNoteページを一発で生成する
Twitterで公式からこんな投稿が上がっていて、 面白かったので紹介。
Is #Excel one of your go-to tools? @Filibuster3 created a quick video to learn how you can make a list in Excel and use it in #OneNote: https://t.co/VoKtINrh5x #tiptuesday #edtech pic.twitter.com/XiVZYztDIY
— OneNote Education (@OneNoteEDU) May 22, 2018
Youtubeはこちら。
ExcelからOneNoteページをつくっちゃおう!というお話。
まずはExcelでリストを用意
Excelでなんらかのリストを作ります。 ネタは何でもいいんですが、機能的に”日付”が一番イメージしやすい。
ので、約1か月分の日付をオートフィルで生成する。
※オートフィルしらねって方はまずExcelから勉強する。

OneNoteのどっかにペースト
適当なページにコピペ。

ペーストした表全体を選択して右クリック
「ページへのリンク」を選択

どん!

ずらっと日付ページが並ぶというオチ。
中身は日付をタイトルにした白紙ページが生成されています。

日報?レポート?とかには便利そうですね。
もちろん、トップページは目次としてリンクが機能するので、検索もらくちん。
OneNote × シンタックスハイライト = 最強
OneNote標準の機能ではOneNote上のシンタックスハイライトはサポートされていません。
ちょっとコードをメモっておきたいときがあるんすよね。
Qiitaとかブログ、1人Slackに上げるのもいいんですが、
OneNoteもやっぱ便利なのです。
(あ、1人Slack何気に便利なのでいずれ紹介しましょう。)
そこで、シンタックスハイライトが反映されているテキストを OneNote上で表示させる方法を紹介。
VSCodeを使う
みんな大好きVisual Studio Codeを使う方法が一番楽かも。
(他のエディタでは試していないけどたぶんいけるんじゃないかな・・・。)
まずは普通にVSCodeに入力。

OneNoteにコピペ。

コピペ後のカラーはたぶんVSCodeでのテーマに依存するはず。
これだけでは記事にした意味がないので、もう一つ面白いアドインをご紹介します。
NoteHighlightアドイン
いくつか似たようなアドインがあるようですが、こちらが無料で公開されているもの。
こんな感じのリボンが出来て、

コードを貼り付けると・・・

どやぁ

なんか枠ができるんですね。
結論
まぁ、自分にあった環境を使うのが一番でしょうかねぇ。 個人的にはあらゆるリンクや気になったコードをメモメモできるSlackは便利だなぁと思うのです。 ・・・・タイトルのOneNote最強どこいった?
pandas-profilingが探索的データ解析にめちゃめちゃ便利だった件
当たり前の話だったら超恥ずかしいのですが、初めて知って驚愕したのでご紹介。
タイトルのとおり、pandas-profilingが探索的データ解析(EDA)にめちゃめちゃ便利だったのでご紹介するだけの記事です。
pandas-profilingの詳細はこちらからご確認を。 pandas-profiling
準備
pipやAnacondaを使うなどして、適宜ご自身の環境にインストール。
pip install pandas-profiling
あとはインポートするだけ。
import pandas as pd import pandas_profiling as pdp
実行
みんな大好きTitanicのtrainデータを使用。 なんの前処理もかけずに実行してみる。
df = pd.read_csv('train.csv')
pdp.ProfileReport(df)
Output
こんな感じでデータの全体像をHTMLで出力してくれます。便利。
画像
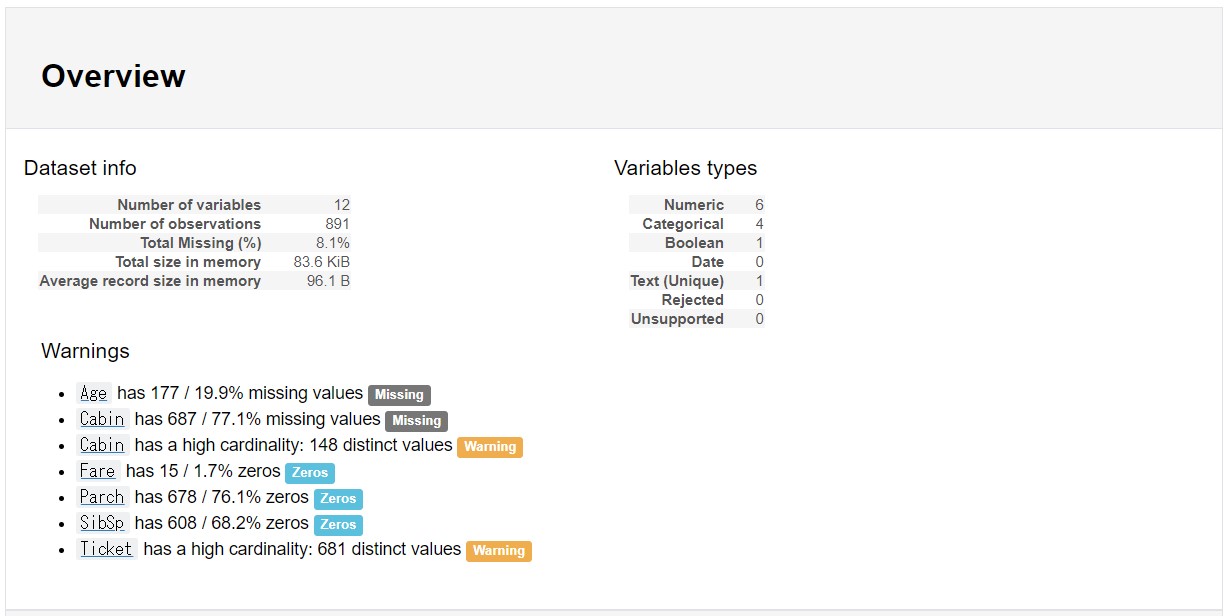

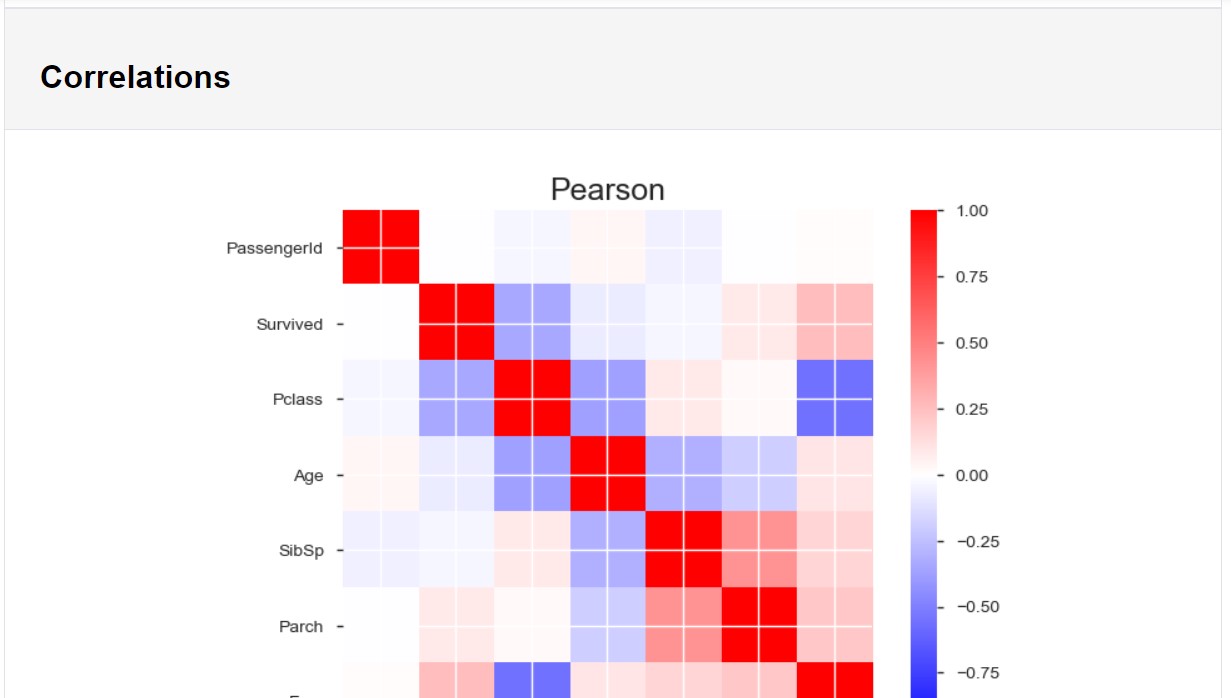
gif

データフレームの構造に、データ型別の基本統計量とグラフ、 数値データはピアソンの積率相関とスピアマンの順位相関といったところでしょうか。
膨大な説明変数があると大変そうですが、 1行のコードでここまで出してくれるのはEDAが捗りそうですねぇ。
また、以下でHTMLファイルの作成も可能。
profile = pdp.ProfileReport(df)
profile.to_file(outputfile="myoutputfile.html")
注意
Colaboratoryでやると表示、挙動が不安定でした。 Kaggle KernelはOK。
Colaboratoryでは何か方法があるかもしれません。 IT詳しい方、ご存知でしたら教えてください。
補足(2018/05/06追記)
プロフェッショナルの方がcolaboratory挙動の解決策記事を書いてくれています! HTMLファイルを生成して、埋め込む感じでうまくいくようです!
アイデアが形になる瞬間を刮目せよっ!インクストロークの再生
先日の記事を踏まえて、僕もWin10版アプリの機能をちょっと学ばないとと思っていたらこんなマークがリボンに。

再生?
なんのこっちゃ?埋め込みYoutubeとかのコンテンツでも再生する機能か?
と思って調べたらこんな感じでした。
Windows 10 の OneNote でのインク ストロークを再生する
ほう。
書いた順に再生される機能のようです。
これ、インクストロークだけじゃないようですね。

だから何だ感満載。
クリエイティブな人種の方が、
「おれのアイデアが形になる過程そんなにみたい?」
って場面があったら公式HPみたいになるのかな?
とりあえずタブレットで使わない派の自分には半世紀に一度も訪れないシチュエーションであろう。
【第3回】Python Marketing Data Analytics! ~集計と検定~
さて、前回に引き続き、今回は集計・検定を実施してデータの理解をさらに深めたいと思います~。 ただし、データが大きいので、検定はあくまで方法論だけって感じですね。
集計
集計は、可視化と並び、データの基本的な傾向を把握するために必須といっていいと思う。 集計した上で可視化するなども必要だ。
少し前処理を行えば、数値・カテゴリー、いずれの場合でも実施可能である。 さっそく実施してみよう。
まずはいつもどおり、headを確認するところから。
df.head(3)
| age | job | marital | education | default | balance | housing | loan | contact | day | month | duration | campaign | pdays | previous | poutcome | y | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 30 | unemployed | married | primary | no | 1787 | no | no | cellular | 19 | oct | 79 | 1 | -1 | 0 | unknown | no |
| 1 | 33 | services | married | secondary | no | 4789 | yes | yes | cellular | 11 | may | 220 | 1 | 339 | 4 | failure | no |
| 2 | 35 | management | single | tertiary | no | 1350 | yes | no | cellular | 16 | apr | 185 | 1 | 330 | 1 | failure | no |
グラフ化の際、yの構成は、noが大半を占めることがわかっている。
正確な件数を集計してみたい。
df['y'].value_counts()
no 4000
yes 521
Name: y, dtype: int64
その他、オブジェクトの変数の各項目別の集計値を確認する。
item = np.array(df.describe(include='O').columns) for i in item: print('【%(i)s】' %locals()) print(df[i].value_counts()) print('-'*30)
【job】
management 969
blue-collar 946
technician 768
admin. 478
services 417
retired 230
self-employed 183
entrepreneur 168
unemployed 128
housemaid 112
student 84
unknown 38
Name: job, dtype: int64
------------------------------
【marital】
married 2797
single 1196
divorced 528
Name: marital, dtype: int64
------------------------------
【education】
secondary 2306
tertiary 1350
primary 678
unknown 187
Name: education, dtype: int64
------------------------------
【default】
no 4445
yes 76
Name: default, dtype: int64
------------------------------
【housing】
yes 2559
no 1962
Name: housing, dtype: int64
------------------------------
【loan】
no 3830
yes 691
Name: loan, dtype: int64
------------------------------
【contact】
cellular 2896
unknown 1324
telephone 301
Name: contact, dtype: int64
------------------------------
【month】
may 1398
jul 706
aug 633
jun 531
nov 389
apr 293
feb 222
jan 148
oct 80
sep 52
mar 49
dec 20
Name: month, dtype: int64
------------------------------
【poutcome】
unknown 3705
failure 490
other 197
success 129
Name: poutcome, dtype: int64
------------------------------
【y】
no 4000
yes 521
Name: y, dtype: int64
------------------------------
比率でも確認してみる。
item = np.array(df.describe(include='O').columns) for i in item: print('【%(i)s】' %locals()) print(df[i].value_counts(normalize=True)) print('-'*30)
【job】
management 0.214333
blue-collar 0.209246
technician 0.169874
admin. 0.105729
services 0.092236
retired 0.050874
self-employed 0.040478
entrepreneur 0.037160
unemployed 0.028312
housemaid 0.024773
student 0.018580
unknown 0.008405
Name: job, dtype: float64
------------------------------
【marital】
married 0.618668
single 0.264543
divorced 0.116788
Name: marital, dtype: float64
------------------------------
【education】
secondary 0.510064
tertiary 0.298607
primary 0.149967
unknown 0.041363
Name: education, dtype: float64
------------------------------
【default】
no 0.98319
yes 0.01681
Name: default, dtype: float64
------------------------------
【housing】
yes 0.566025
no 0.433975
Name: housing, dtype: float64
------------------------------
【loan】
no 0.847158
yes 0.152842
Name: loan, dtype: float64
------------------------------
【contact】
cellular 0.640566
unknown 0.292856
telephone 0.066578
Name: contact, dtype: float64
------------------------------
【month】
may 0.309224
jul 0.156160
aug 0.140013
jun 0.117452
nov 0.086043
apr 0.064809
feb 0.049104
jan 0.032736
oct 0.017695
sep 0.011502
mar 0.010838
dec 0.004424
Name: month, dtype: float64
------------------------------
【poutcome】
unknown 0.819509
failure 0.108383
other 0.043574
success 0.028534
Name: poutcome, dtype: float64
------------------------------
【y】
no 0.88476
yes 0.11524
Name: y, dtype: float64
------------------------------
これでオブジェクトのデータの全体像も理解できた。
次はyと各変数の結果に関連が無いか確認してみたい。
例えば、定期預金の有無は生活の余裕や階級に深く影響していそうだ。
所得階級が高そうな層は定期預金契約者が多く、階級が低い場合は契約が少ないという傾向があるのではないか。
まずは対象者の仕事別に上記の仮説を検証しよう。
cross1 =pd.crosstab(df['y'], df['job'], margins=True, normalize='index') cross1
| job | admin. | blue-collar | entrepreneur | housemaid | management | retired | self-employed | services | student | technician | unemployed | unknown |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| y | ||||||||||||
| no | 0.105000 | 0.219250 | 0.038250 | 0.024500 | 0.209500 | 0.044000 | 0.040750 | 0.094750 | 0.016250 | 0.171250 | 0.028750 | 0.007750 |
| yes | 0.111324 | 0.132438 | 0.028791 | 0.026871 | 0.251440 | 0.103647 | 0.038388 | 0.072937 | 0.036468 | 0.159309 | 0.024952 | 0.013436 |
| All | 0.105729 | 0.209246 | 0.037160 | 0.024773 | 0.214333 | 0.050874 | 0.040478 | 0.092236 | 0.018580 | 0.169874 | 0.028312 | 0.008405 |
上記で、y別の仕事の構成比(横100%)が把握できる。
が、すこし分かりづらいのでヒートマップを使って加工すると、一目瞭然になる。
plt.figure(figsize=(18,5)) sns.heatmap(cross1, fmt="1.2f", annot=True, cmap="coolwarm") plt.show()

managementが仕事の人はyesの割合が多く、blue-collarが仕事の人はnoの割合が多い。
先の仮説はあながちまちがいではなさそうである。
その他の指標も確認してみたい。
item = np.array(df.describe(include='O').columns) for i in item: cross =pd.crosstab(df['y'], df[i], margins=True, normalize='index') plt.figure(figsize=(15,5)) sns.heatmap(cross, fmt="1.2f", annot=True, cmap="coolwarm") plt.show()










このように、クロス集計を行うことにより、各要因での差を比較することが可能になる。
しかし、クロス集計のみでデータ分析を行い、結論づけることは危険だ。
- 2変数間の比較しかできず、その背後にありうる他の変数の影響を把握できない
- 生じた差が偶然発生したものか判断できない
まず上の論点は、説明変数が別の説明変数の影響を受けている状況を加味できないである。
これが拡張すると、単なる疑似相関の結果を、「相関がある」と誤った結論を導き出してしまうリスクがある。
このため、疑似相関を疑う事前の仮説設計や、多変量解析が重要になる。
疑似相関については以下wikiを参照しただくと良い。
疑似相関
次の論点は、データがビッグデータと呼ばれるほど膨大ではない場合、
生じた差は、説明変数が影響しているのではなく単なるサンプリングの誤差なのではないか?という問いである。
この問いに応える一つの手法が、統計学的検定である。
検定
統計学的検定の理論的な内容は以下を参照いただくとよい。
さっそく、各変数と目的変数yの集計結果について、有意水準0.05で検定を行ってみる。
item = np.array(df.describe(include='O').columns) for i in item: chisq =pd.crosstab(df['y'], df[i], margins=False) chi, p, d, expect = sp.stats.chi2_contingency(chisq) print('【%(i)s】' %locals()) print("p_values : %(p)s" %locals() ) if p < 0.05: print("★有意差あり") else: print("有意差なし") print('-'*30)
【job】
p_values : 1.901391096662705e-10
★有意差あり
------------------------------
【marital】
p_values : 7.373535401823763e-05
★有意差あり
------------------------------
【education】
p_values : 0.001625240003630989
★有意差あり
------------------------------
【default】
p_values : 0.9254599873026758
有意差なし
------------------------------
【housing】
p_values : 2.7146998959323014e-12
★有意差あり
------------------------------
【loan】
p_values : 2.9148288298428256e-06
★有意差あり
------------------------------
【contact】
p_values : 8.30430129641147e-20
★有意差あり
------------------------------
【month】
p_values : 2.195354833570811e-47
★有意差あり
------------------------------
【poutcome】
p_values : 1.5398831095860172e-83
★有意差あり
------------------------------
【y】
p_values : 0.0
★有意差あり
------------------------------
すべて実施すると分かるとおり、default意外はすべてp値が0.05以下、有意差ありと判断されている。
これは検定の性質によるもので、データの量が大きくなるほどp値は低くなる傾向がある。
今回のように5,000弱のデータであると、ほんの少しの差も有意差として判断されてしまう。
ビッグデータ時代の昨今では、あまり統計学的検定の意義は以前よりも少なくなっているのかもしれない。
補足
少し話が脇道にそれるが、数値データを区分し、カテゴリカルデータとして処理することもできる。
df_dummies = df df_dummies['age_categorical'] = 0 df_dummies.loc[df_dummies['age'] <= 20, 'age_categorical' ] = '-20' df_dummies.loc[(df_dummies['age'] > 20 ) & ( df_dummies['age'] <= 40 ), 'age_categorical'] = '21-40' df_dummies.loc[(df_dummies['age'] > 40 ) & ( df_dummies['age'] <= 60 ), 'age_categorical'] = '41-60' df_dummies.loc[df_dummies['age'] >60, 'age_categorical' ] = '60-' df_dummies['age_categorical'].value_counts()
21-40 2425
41-60 1962
60- 127
-20 7
Name: age_categorical, dtype: int64
cross =pd.crosstab(df_dummies['age_categorical'], df_dummies['y'], margins=True, normalize='index') plt.figure(figsize=(10,5)) sns.heatmap(cross, fmt="1.2f", annot=True, cmap="coolwarm") plt.show()

連続的な数値データをカテゴリ化するのは構成比が分かりやすい反面、情報量が削減されるため、 ケースバイケースで判断することとなる。
おわりに
‘pandas‘を使うと集計も楽勝ですね~。 ただ、ここまで紹介したのはあくまで2変数の関係性の話。 おそらく目的変数は多変数の影響を受けていると考えられるので、 今後は多変量解析を焦点にしたいと思いますー。 あ、その前にダミー変数化とか前処理をいれるかも。
とりあえずまたGWに書き溜め&勉強します。