XKCDスタイルによるゆるふわPython Data Visualization
matplotlib の XKCDスタイルを適用して、ゆるふわVizを作ってみようというお話です。
XKCDについては以下をご参照ください。
基本的に、matplotlibオブジェクトの描写コードをwith構文内に仕込めむだけの単純作業です。
import matplotlib.pyplot as plt import seaborn as sns import numpy as np import pandas as pd sns.set() df = sns.load_dataset("titanic")
普通の描写だと
idx = df["embark_town"].value_counts().index val = df["embark_town"].value_counts().values width = 0.6 plt.figure(figsize=(8,4),facecolor="white") plt.barh(idx, val, width) for x, y in zip(val, idx): plt.text(x, y, x, ha='left') plt.ylabel('Embark town') plt.title('Record counts by embark town') plt.show()

XKCDスタイルを適用してみます。
with plt.xkcd(): width = 0.6 plt.figure(figsize=(8,4),facecolor="white") plt.barh(idx, val, width) for x, y in zip(val, idx): plt.text(x, y, x, ha='left') plt.ylabel('Embark town') plt.title('Record counts by embark town') plt.show()

seabornの統計グラフでもきちんと機能します。
with plt.xkcd(): plt.figure(figsize=(8,5),facecolor="white") sns.distplot(df[df["survived"]==1]["age"]) sns.distplot(df[df["survived"]==0]["age"]) plt.legend(["survived : 1","survived : 0"]) plt.title("Age distribution by survived") plt.show()

scatter plot系はそんなに変わり映えしません。
np.random.seed(19680801) N = 100 r0 = 0.6 x = 0.9 * np.random.rand(N) y = 0.9 * np.random.rand(N) area = (20 * np.random.rand(N))**2 c = np.sqrt(area) r = np.sqrt(x ** 2 + y ** 2) area1 = np.ma.masked_where(r < r0, area) area2 = np.ma.masked_where(r >= r0, area) with plt.xkcd(): plt.figure(figsize=(6,6),facecolor="white") plt.scatter(x, y, s=area1, marker='^', c=c) plt.scatter(x, y, s=area2, marker='o', c=c) theta = np.arange(0, np.pi / 2, 0.01) plt.plot(r0 * np.cos(theta), r0 * np.sin(theta)) plt.show()

個人的にbox plot、violin plotの描写が可愛らしくてすきです。
with plt.xkcd(): f, ax = plt.subplots(figsize=(7, 6)) ax.set_xscale("log") planets = sns.load_dataset("planets") sns.boxplot(x="distance", y="method", data=planets, whis=[0, 100], palette="vlag") sns.swarmplot(x="distance", y="method", data=planets, size=2, color=".3", linewidth=0) ax.xaxis.grid(True) ax.set(ylabel="") sns.despine(trim=True, left=True)

Horizontal boxplot with observations — seaborn 0.10.1 documentation
sns.set(style="whitegrid", palette="pastel", color_codes=True) tips = sns.load_dataset("tips") with plt.xkcd(): plt.figure(figsize=(6,4)) sns.violinplot(x="day", y="total_bill", hue="smoker", split=True, inner="quart", palette={"Yes": "y", "No": "b"}, data=tips) sns.despine(left=True)

Grouped violinplots with split violins — seaborn 0.10.1 documentation
たまーに使ってみたくなる楽しげなstyleです。 多少のジョークがきくプレゼンや、資料に差し込んでみるのがよさそうです。

Google Map API を利用した Python によるジオコーディング
いろんなデータを漁ってると、住所だけの情報を扱うことがでてきます。
よほど整備されたデータでない限り、緯度・経度なんてついてないことが多い。。。
私は地理データが大変苦手なんですが、どうしても正確な位置情報をダッシュボード上にプロットする必要があったので、
Pythonでジオコーディングします。
ググってみると色々やり方はあるようなのですが、
既にエラーで出来ないコードも多かったので、確実なGoogle Map APIとgooglemapsを使った方法にします。
Google Map API の使用
GCPでGeocoding APIを取得するだけの作業です。
ソースは以下のような詳しいサイトがたくさんあるので、これらに従えば大丈夫です。
取得できたらAPIキーをコピっておきます。

Python
利用するのは googlemaps です。
試しにマイホームタウンの横浜市役所の住所をぶちこんでみます。
#!pip install googlemaps import googlemaps googleapikey = 'ここにAPIキーを入れる' gmaps = googlemaps.Client(key=googleapikey) gmap_list = gmaps.geocode("横浜市中区港町1-1") ll = gmap_list[0]["geometry"]["location"] print("Latitude : ",ll["lat"]) print("Longitude : ",ll["lng"])
無事、緯度経度を取得できたようです。

実際に横浜市役所の位置か検証します。
先生!ばっちりでありんす!
これで適当にリストで住所をながせば、緯度経度情報が簡単に揃えられそうです。
※APIの使用制限や料金はちゃんと検討しないと・・・。まだ詳しくないです。すみません。
ちょっとだけ、地理データと仲良くなれた気がしたデータ遊びでした。
Google Colaboratory からKaggle API を叩く
過去にQiitaに書いたことがありますが、
こちらにもメモとして再度検証、記録に残します。
Kaggle APIの公式リファレンスはこちら
Kaggle json のダウンロード
My Accountから、API Tokenを作成、kaggle.jsonをダウンロードします。

以下、google drive上に先ほどのjsonを格納

Colaboratory
以下、pipからkaggleモジュールをインポート
!pip install kaggle
google driveにマウント、必要があれば適当にカレントディレクトリを設定します。
import os from google.colab import drive drive.mount('/content/drive') os.chdir("/content/drive/My Drive/hoge/hogehoge")
先ほど読み込んだjsonファイルからusernameとkeyを環境変数に読み込みます。
import os import json f = open("/content/drive/My Drive/kaggle.json", 'r') json_data = json.load(f) os.environ['KAGGLE_USERNAME'] = json_data['username'] os.environ['KAGGLE_KEY'] = json_data['key']
以上で準備は終わりです。簡単でした。
api
上記処理で、あとはapiを叩くだけです。
現在開催されているコンペティションリストはこれ。
!kaggle competitions list

試しに現在開催されている以下コンペのデータをカレントディレクトリにダウンロードしてみます。
Dataタブに表記されているapiを、colaboratoryにコピペするだけです。

!kaggle competitions download -c m5-forecasting-uncertainty

無事全ファイルダウンロードされていました。
また、この例ではデータはzip形式になっていますが、
pandas.read_csvはzipのまま読み込むことが可能です。
import pandas as pd train = pd.read_csv("sales_train_validation.csv.zip") print(train.shape) display(train.head())

無事、ちゃんと読み込めていそうな感じでした。
appendix
過去から記事を漁るといろいろでてきますので、お好きな方法で実装すればよろしいかと思います。
【Pythonメモ】Google ColaboratoryでKaggle APIを使うおまじないコード&作法 - Qiita
Easy way to use Kaggle datasets in Google Colab | Data Science and Machine Learning
Ternary plot をTableauで実現する
Ternary Plot、3次元プロット?をTableauで実装してみます。
Tearnary Plotは3次元の構成要素を正三角形内にプロットするVizです。
Tableau Public に Tearnary Plot のサンプルが多々 Publish されているので、
それを見ていただくとイメージがつかめます。
僕もこれらを参考に、以下設計していきます。
データ
e-statから市区町村の年齢3階級別人口を取得しました。
この3カテゴリの構成比データを2次元座標データに加工し、 Tableau上でTernary Plotとして描写するのが本記事のゴールです。
上記e-statでデータを加工し、以下のデータを取得します。

余計な情報はcsv上で処理し、Tableauへ渡します。
Tableau上での描写
Tableauに渡した段階のデータはこちらになります。

ここから、以下のとおり構成比のメジャーを作成します。

このデータをどう2次元座標データにするかという問題には、wikipediaに答えがあります。
以下計算式により、3次元のa,b,cデータをデカルト座標にプロットできます。*1

TableauでX, Yのメジャーを以下のとおり作成します。
/// X (1/2) * ( (2*[B:15-64]+[C:65]) / ([A:-15]+[B:15-64]+[C:65]) )
///Y (SQRT(3)/2) * ( [C:65] / ([A:-15]+[B:15-64]+[C:65]) )
あとはX, Yのメジャーを行列に配置し、 詳細に市町村名を配置、適当に都道府県等のディメンションで色分け、pointの大きさを人口にしてみます。
X,Yの軸の範囲は0~1に固定しておきましょう。 また、レポートの背景色・罫線などの情報は削除しておきます。

別にダッシュボードを作成、 背景に上記wikipediaで公開されているTernary Plotの画像を適当に拝借しましょう。
{kind=link}
設置した背景の上に作成したレポートを浮動オブジェクトで合わせます。

これで完成、全国市区町村の年齢3階級別構成比を2次元のTernary Plotで表現できました。

Public Garrary上の動かせるデータはこちらです。
appendix
正直、市区町村年齢構成の大勢はそこまで変わりませんので、
DataViz作品としては微妙でしたね。
もう少し時系列データで遷移を見たりすると面白いかもしれません。
3次元かつ、それぞれの軸が百分率で表現できる指標にすると、こちらのVizで表現できます。
機会があったら他の例もつくってみたいと思います。
商品購買のアソシエーションルールをネットワークで可視化する
アソシエーション分析の概略
アソシエーション分析は、商品の何と何が一緒に買われやすいのか?を示すための分析手法です。
「アソシエーション分析」とか「アソシエーションルール」とかをググると大量の記事が出てきますので、詳細はそちらの記事を参考にしてください。*1
以下、本記事中で重要になる点だけ記載します。
支持度(support)
総購買ユーザーNのうち、商品Aと商品Bを同時に買っている人の割合です。

信頼度(confidence)
商品Aを買った人のうち、商品Bを購入した人の割合です。

リフト(lift)
商品Aを買った人のうち商品Bを購入する人の割合(信頼度)が、
そもそも総購買ユーザーNにおける商品Bの購入率より高いか低いか、を表します。

一般的には、ある程度の支持度がある購入パターンのみで線引きし、リフト値を見て商品ごとの連関強弱を計ります。
今回の目的は、アソシエーションルールをネットワークで可視化し、商品ごとの連関を分かりやすく表現できるか検証します。
ネットワークは、Pythonのnetworkxを利用し、Tableauで描写することにします。
SQLによるデータ抽出
自身のお仕事にも活かせるよう購買データを使います。
postgresqlが提供してくれているDVDレンタルのサンプルデータを使用することにします。
ただし、バスケット(同レシート内購買)単位での分析は難しいので、ユーザー単位で集計することとします。
サンプルデータとER図はここで確認できます。

これを自身のDB環境に入れます。
以下、SQLで上記指標に必要なA∩B, A, B, Nを集計します。*2
with item as ( select inventory_id , title , name from --- 中略------------------------------------------ inner join( select tran.title , count (distinct customer_id) as "B" from tran group by tran.title ) as target_table on fromto.target_item = target_table.title ;
※正直汚いSQLです。すみません。
気になる方は以下GitHubをご確認いただければと思います。
こんな感じのテーブルに仕上がりました。

ここから、support, confidence, liftの算出とネットワーク座標の生成はPythonに渡します。
Python・networkxによる node座標データの作成
ここは、先般のブログどおり、netowrokxでTableauに取り込むテーブルデータを準備します。
まず、support , confidence , lift を計算します。
さらにAandBの出現UUが少ない組み合わせは除外してしまいましょう。
import pandas as pd edge_df = pd.read_csv("output.csv") # 以下、support , confidence , liftを計算します。 edge_df["support"] = edge_df["AandB"] / edge_df["N"] edge_df["confidence"] = edge_df["AandB"] / edge_df["A"] edge_df["lift"] = edge_df["confidence"] / ( edge_df["B"] / edge_df["N"] ) # supportが低い組み合わせを除外します。 edge_df = edge_df[edge_df["AandB"]>3] display(edge_df) print(edge_df.shape)
本来はconfidenceとliftの両方を考察すべきですが、
一旦liftだけをweightとしてみました。
edge_df_lift = edge_df[["source_item","target_item","confidence"]] col_name = ["source", "target","weight"] edge_df_lift.columns = col_name import networkx as nx def make_network(df): G = nx.from_pandas_edgelist(df,edge_attr=True) pos = nx.spring_layout(G) edges = G.edges() weights = [G[u][v]['weight'] for u,v in edges] nx.draw(G, pos, edges=edges, width=weights, node_size=10, node_color="c",with_labels=False) node = [] x = [] y = [] for k,v in pos.items(): node.append(k) x.append(v[0]) y.append(v[1]) node_df=pd.DataFrame({ "item":node, "X":x, "Y":y }) return node_df node_df = make_network(edge_df_lift)
・・・一応netowrokxでの画像出力していますが、完全に意味不明な感じになっています。

結果が見える戦いをするのはつらいですが、Tableau化まで以前と同じ手順で進めます。
result_df_1 = pd.merge(edge_df_lift,node_df,how="left",left_on="source",right_on="item") result_df_2 = pd.merge(edge_df_lift,node_df,how="left",left_on="target",right_on="item") result_df = pd.concat([result_df_1, result_df_2]) result_df["edge_name"] = result_df["source"] + "_" + result_df["target"]
Tableau上での可視化
手順は上にあげた過去記事とおりですので省略します。
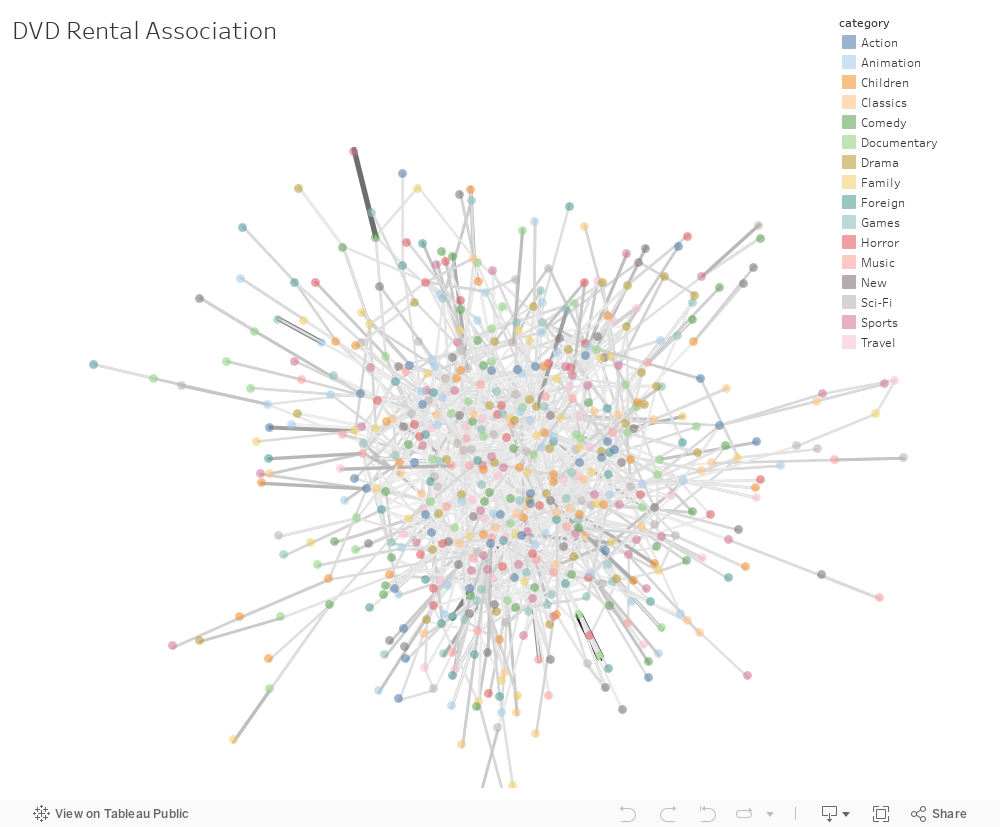
なんとなく、lift(weight)が明らかに高い組み合わせもありますが、全体のネットワークの傾向としては解釈が難しいですね。
networkx側でもう少し手を加えるべきなのでしょうか・・・?
そもそも購買データをネットワークグラフにするのが適切ではない・・・?
あるいはサンプルデータだからランダマイズされてるとか・・・?
技術・知識的な未熟さが原因か、そもそもデータの話かは検証する余地がありそうですが、 面白い試みだったかなぁと思います。
【随時更新】誰にも教えたくないBIダッシュボードデザインに便利なサイト集を晒す
デザイン・分析アイデア
From data to Viz | Find the graphic you need
デザイン素材
配色ツール
https://color.adobe.com/ja/create/color-wheel/color.adobe.com
データ
https://archive.ics.uci.edu/ml/index.phparchive.ics.uci.edu
appendix
気になったものなど、随時更新していきます。