Numpyroでベイズ統計モデリング~単回帰モデル~
かれこれ数年付き合ってきたstan ですが、
推定の遅さが仕事上かなりネックになっており、
メインで使うPPLを高速にMCMCを回せるNumpyroに変えようと模索中。
以下、RとStanで始めるベイズ統計モデリングによるデータ分析入門のデータ&分析内容を題材に、Numpyroで実装しながら練習する記録です。
")
※可視化用ライブラリの arviz もちょっと使ってない間にだいぶ高機能になっており、その辺も試していく所存。
準備
環境はgoogle colabです。
import jax.numpy as jnp import numpy as np import jax.random as random import pandas as pd import matplotlib.pyplot as plt import seaborn as sns sns.set(style='darkgrid',palette='bright') #!pip install numpyro import numpyro import numpyro.distributions as dist from numpyro.infer import MCMC, NUTS numpyro.set_host_device_count(4) import arviz as az
データの準備・確認
データは以下サポートサイトより
file_bear_sales_2 = pd.read_csv("3-2-1-beer-sales-2.csv")
file_bear_sales_2.head()
元データはsalesとtemperatureの1変量による単回帰モデル用。

plt.figure(figsize=(10,5)) sns.scatterplot(x="temperature",y="sales",data=file_bear_sales_2) plt.show()
データ分布は以下のような形。

モデル
単回帰モデルなので非常に単純。

※はてぶのTexが全く表示されなかったり、よくわからないエラー起こるので作法が謎。
def model( sales, temperature ): Intercept = numpyro.sample("Intercept",dist.Normal(0,100)) beta = numpyro.sample("beta",dist.Normal(0,100)) sigma = numpyro.sample("sigma",dist.HalfNormal(100)) numpyro.sample("sales",dist.Normal(Intercept + beta * temperature, sigma),obs = sales)
Numpyro のいいところはモデルの記述が直感的でわかりやすいところ。
後に取り組む階層モデルもわかりやすい。
一方で、時系列には jax.lax.scan を使うのが肝要なんですが、一気に複雑になる。
ここもいずれ実装して理解を深めていきたい。
data_dict = {
"temperature":file_bear_sales_2["temperature"].values,
"sales":file_bear_sales_2["sales"].values
}
kernel = NUTS(model)
sample_kwargs = dict(
sampler=kernel,
num_warmup=2000,
num_samples=2000,
num_chains=4,
chain_method="parallel"
)
mcmc = MCMC(**sample_kwargs)
mcmc.run(random.PRNGKey(0), **data_dict)

MCMC回すのもそうなんですが、コンパイルいらないので、体感ものすごく早い。
4000サンプリングで1chain12秒。
並列処理、GPU利用も簡単なので、アクセラレータを最大限活かせる。
結果
mcmc.print_summary()

結果はほぼ本紙と同一になりました。
arviz でトレースプロットを確認してみる。
idata = az.from_numpyro(mcmc) az.plot_trace(idata, figsize=(16,9)) plt.show()

r_hat でも確認できるとおり、収束も問題なしです。
所感
Numpyro は stan と比べるとかなり高速にMCMCを回せるし、
比較的(TFPとかと比べれば)理解しやすい記述であることもポイントの一つ。
事前分布を必ず明示しなきゃいけないので、stanのデフォルト無情報事前分布に慣れてるとちょっと面倒です(恥
時系列はいずれ取り組みたいが、ちょっとモデル記述がややこしくなるので、そこはやっぱり stan のほうが分かりやすい(単に慣れてるだけ説が濃厚ですが。)
次は事後予測分布の可視化が焦点です。
log_level_modelのパラメータ解釈
乗法モデル
単純なGLMにおいて、目的変数・説明変数(もしくは片方のみ)を対数変換したほうがより解釈しやすいケースがあります。
一般的に、目的変数・説明変数ともに対数変換したモデルは乗法モデル(弾力化モデル)と言われるようです。
(参考) 対数変換を行う意味について。回帰分析において対数変換する背景にある前提とは?|アタリマエ!
計量経済学分野では比較的ポピュラーな方法ですが、
使おうと思ったときに対数変換によってパラメータの解釈が代わる証明が不安だったので備忘録的に書きます。
なお、ここでは目的変数のみを対数変換する log-level-model になります。(※log-logがいいのか、level-logがいいのかはモデルの当てはまりや課題に応じて決めたほうが良さそうです)
log-level-modelのパラメータ解釈は、説明変数1単位の増加による目的変数の増加率(%)になるはずです。
(参考) Data Science Simplified Part 7: Log-Log Regression Models | by Pradeep Menon | Towards Data Science
証明
$$ \begin{eqnarray} \log y &=& \alpha + \beta x + \epsilon \ \end{eqnarray} $$
まず両辺を微分し、
$$ \begin{eqnarray} \dfrac{d}{dx} \log y &=& \dfrac{d}{dx} (\alpha + \beta x + \epsilon) \\ \beta &=& \dfrac{d \log y}{dx} \end{eqnarray} $$
ここで、合成関数の微分公式より
$$ \begin{eqnarray} \dfrac{d \log y}{dx} &=& \dfrac{d \log y}{dy} \cdot \dfrac{dy}{dx} \tag{1} \end{eqnarray} $$
$(1)$右辺の $d \log y / dy$ は対数関数の微分公式より
$$ \begin{eqnarray} \dfrac{d \log y}{dy} &=& (\log y)' &=& \dfrac{1}{y} \end{eqnarray} $$
したがって $(1)$ は以下のとおり
$$ \begin{eqnarray} \dfrac{d \log y}{dy} \cdot \dfrac{dy}{dx} &=& \dfrac{1}{y} \cdot \dfrac{dy}{dx} \\ &=& \dfrac{dy/y}{dx} \end{eqnarray} $$
よって、 $$ \begin{eqnarray} \beta &=& \dfrac{dy/y}{dx} \end{eqnarray} $$
- $dy/y$ は $y$ の増加率
- $dx$ は xの増加量
以上により、パラメータ$\beta$ は$x$の増加量に対する$y$の増加率であることが証明できました。
なお、log-log-modelも同じ手順で証明できます。
無事、log-level-modelのパラメータの解釈が理解できたところで、実データで解釈性を見ていきます。
利用データ
df = sns.load_dataset("tips")

支払額や性別、人数などに応じて、チップがいくら払われたかのデータセットのようです。
これを題材にしていきます。
なお、モデリングには以下のようにダミーデータ化し、簡単のためdayは除外しています。

データの概観
目的変数とするtipは以下のような分布となっており、やや右すそが長い対数正規分布に近い形です。

データ上0以下にはならないため、ここだけ見ても通常の正規分布を仮定した一般線形モデルはあまり適さなそうであることが分かります。
が、今回の趣旨はパラメータ解釈の違いを見たいのでこの辺は論点にしません。
level-level-model
まずはlevel-level-model、つまり単純な一般線形モデルでのモデリング結果です。
level_level_model = """ data { int N ; // データ数 int C ; //説明変数カラム数 matrix[N,C] X ; //説明変数 vector<lower=0>[N] Y ; // tip 目的変数 } parameters{ vector[C] b ; //パラメータ real<lower=0> s_Y ; //標準誤差 } model { Y ~ normal(X*b, s_Y) ; } generated quantities { real y_pred[N]; y_pred = normal_rng(X*b, s_Y) ; } """
log-level-model
次いで、log-level-model
log_level_model = """ data { int N ; // データ数 int C ; //説明変数カラム数 matrix[N,C] X ; //説明変数 vector<lower=0>[N] Y ; // tip 目的変数 } parameters{ vector[C] b ; //パラメータ real<lower=0> s_Y ; //標準誤差 } model { log(Y) ~ normal(X*b, s_Y) ; } generated quantities { real y_pred[N]; y_pred = normal_rng(X*b, s_Y) ; } """
本来はWAICやWBICで評価したり、バリデーションデータセットで評価すべきなのでしょうが、
こちらも簡単のため(めんどくさい)とりあえず目的変数Yと事後予測分布のEAP推定量のMAEで評価してみました。
print("MAE") print("level-level-model : ",mean_absolute_error(df_fix["tip"],fit_level_level.extract()["y_pred"].mean(axis=0))) print("log-level-model : ",mean_absolute_error(df_fix["tip"],np.exp(fit_log_level.extract()["y_pred"].mean(axis=0))))
MAE
level-level-model : 0.736165905967111
log-level-model : 0.7633751430630242
うーん、log-level-modelのほうが悪いですね(爆)
この辺は自分のモデリングや評価が適当だったりすることにも起因する気がするので、あまり気にしないようにしましょう(白目)
パラメータ評価
level-level-modelとlog-level-modelのパラメータのEAP推定量は以下のとおりです。

例えばsexを見ると、(ここではFemale = 1, Male = 0)
女性の場合level-level-modelでは0.026ドル(?) 男性より多くチップを払うことが期待されます。
一方log-level-modelでは、1.3%多く払うことが期待できます。
解釈の違いは上記の言葉のとおりですが、モデルの前提としては大きく異なります。
level-level-modelでは「どんなに高額な食事をして、大人数でも女性なら0.026ドル多く払うだけ」と考えています。
一方、log-level-modelは「総支払額が高ければ高いほど、女性の場合チップ支払い額が1.3%多くなる」と考えています。
なんとなくですが、10ドルの食事をしたケースと100ドルの食事をしたケースでは、チップの支払額も相対的に高くなりそうです。
このように、変数の影響の解釈とモデルの考え方が、対数変換するだけでかなり変わってくることがわかります。
うまく取り扱えば、マーケティングのための顧客理解や現象理解に役立てることができると思います。
おまけ
チップ支払い額には個人差が大きく関与しそうな気がします。
(これはダミーデータかもしれませんが・・・)
個人差 $mu$ をモデルに入れた階層モデルでもやってみました。
multi_log_level_model = """ data { int N ; // データ数 int C ; //説明変数カラム数 matrix[N,C] X ; //説明変数 vector<lower=0>[N] Y ; // tip 目的変数 } parameters{ vector[C] b ; //パラメータ vector[N] mu ; //個人差 real<lower=0> s_Y ; //標準誤差 real<lower=0> s_mu ; //個人差誤差 } model { mu ~ normal(0, s_mu) ; log(Y) ~ normal(X*b + mu, s_Y) ; } generated quantities { real y_pred[N]; y_pred = normal_rng(X*b + mu, s_Y) ; } """
さてMAEは、
MAE
level-level-model : 0.736165905967111
log-level-model : 0.7633751430630242
multi-log-level-model : 0.31669395645238413
ほかと比べるとダントツで低いですね(当たり前なんですが)
個人差を考慮すると、パラメータの解釈も少し変わります。

通常のlog-level-modelは個人差を一切無視し、データ化された変数に応じてチップが決まるモデルです。
一方、階層モデルだと、データ化されていない個人差が背景にあることを仮定しているので、その影響を除いた本来の各説明変数の効果が計測されていると解釈することができます。
・・・と、ここまで書いておいて、個人差を考慮した真の効果というのは論理の飛躍で拡大解釈なのではないか?と考えてしまいました・・・。 その辺までちゃんと勉強していきたいと思うので、階層モデルの件はおまけ程度にとどめておきます。
モーメント母関数の定義と、期待値・分散の導出
モーメント母関数を利用した期待値と分散の導出
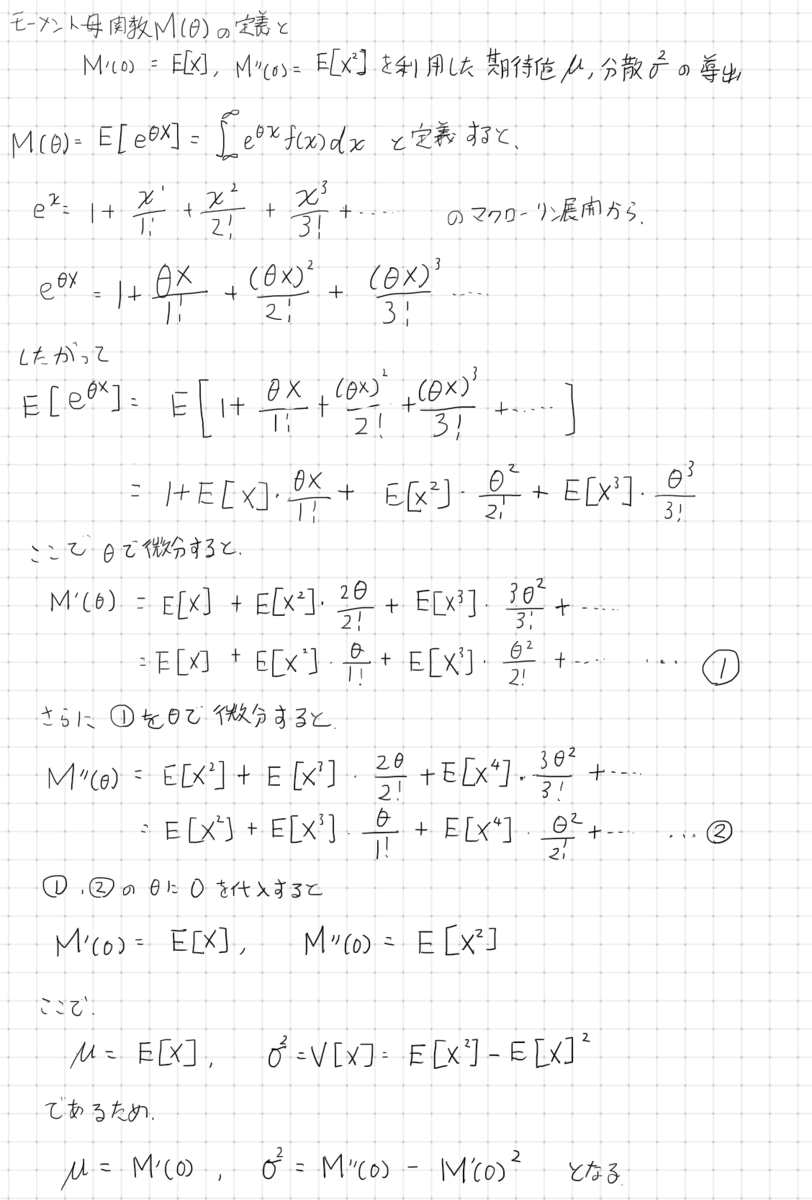
二項分布→ポアソン分布導出
二項分布 B(n,p)のnpを一定とし、n→∞にするとポアソン分布 Po(λ)になります。
その導出過程をまた書きました。(間違ってたらごめんなさい)

Combinationの変換とかe導出のための指数公式の利用とかテクニカルすぎて完全忘れてたので、
よい復習になったよ。。。。
Binomial(n,p)の期待値・分散導出
ペンタブ練習。 二項分布の期待値と分散を導出する公式です。

多少慣れると細かい文字書くのもイケますねー。
ペンタブうんぬん以前に、 そもそもちょっと字が汚い・・・・
同ディレクトリ内データ結合はExcelで超簡単にできることが全世界に広まってほしい
今日のお悩み
あるディレクトリ内に、同じようなCSV・xlsxをたくさんつくって、後で結合しなきゃいけない
とか
100個レイアウトが同じデータがあるんだけど結合作業が死ぬ
とかで困ったことがある人は絶対いると思うんですが、
Excelで一発ですよ。
というお話です。
Power Queryを知らなくても簡単
機能的には Power Queryという機能なんですが、知らなくても大丈夫。 クリックだけでできちゃう。
こんなデータ構造はお仕事でよく見る話

ちなみに中に入っているのは全部同じテーブル構成。
サンプルはちょっとだけですが、100ファイル・100ディレクトリあったらうんざりです。
Excelのデータタブ > データの取得 > ファイルから > フォルダーから

たくさんデータファイルが入っているディレクトリのパスをコピペすると・・・

勝手に一覧で読み込んでくれました
あとは結合を押して読み込むと。

ちゃんとテーブルにしてくれましたー!
ちなみにSource.Nameでファイル名もカラム化してくれるので大変に良き。
Excel Power Queryに詳しくなれば、 多少カラム内容が違うものでも処理できるようにプログラムできます。
データが100個あってもあきらめないでくださいませ。