RとStanで始めるベイズ統計モデリングによるデータ分析入門のNumpyro実装第3回。
")
本日は第3部第6章のダミー変数と分散分析モデルです。
データ準備
# インポート import jax.numpy as jnp import numpy as np import jax.random as random import pandas as pd import matplotlib.pyplot as plt import seaborn as sns sns.set(style='darkgrid',palette='bright') !pip install numpyro import numpyro import numpyro.distributions as dist from numpyro.infer import MCMC, NUTS numpyro.set_host_device_count(4) import arviz as az # データ取得 sales_weather = pd.read_csv("3-6-1-beer-sales-3.csv")
対象データは、カテゴリ変数となる weather 別のsalesを推定する問題。
カテゴリ変数により連続変数を推定する分散分析と呼ばれるモデルです。
sns.violinplot(data=sales_weather, x="weather", y="sales",bw=0.4)
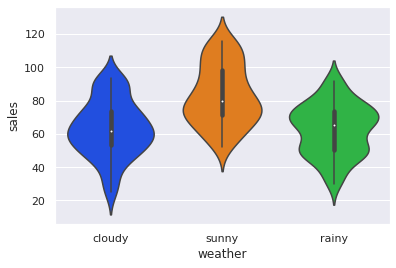
上記のとおり、sunnyのときに sales が高くなり、cloudy , rainy 間は大きな差は見られません。
これをベイズ推定でモデリングしていきます。
モデル
本紙同様、このモデルにもとづき推定します。
カテゴリ変数となる weather を、ダミー変数化するのがポイントです。
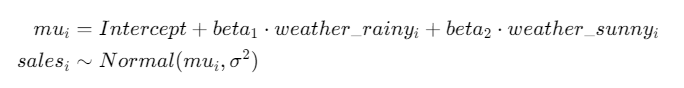
def model( N, sales, rainy, sunny ): Intercept = numpyro.sample("Intercept",dist.Normal(0,100)) weather_rainy = numpyro.sample("wether_rainy",dist.Normal(0,100)) weather_sunny = numpyro.sample("weather_sunny",dist.Normal(0,100)) sigma = numpyro.sample("sigma",dist.HalfNormal(100)) with numpyro.plate("N",N): mu = Intercept + rainy * weather_rainy + sunny * weather_sunny numpyro.sample("sales",dist.Normal(mu, sigma),obs = sales) # データ sales_weather_2 = pd.get_dummies(sales_weather).drop("weather_cloudy",axis=1) data_dict = { "N":len(sales_weather_2), "sales":sales_weather_2["sales"].values, "rainy":sales_weather_2["weather_rainy"].values, "sunny":sales_weather_2["weather_sunny"].values }
kernel = NUTS(model) sample_kwargs = dict( sampler=kernel, num_warmup=2000, num_samples=2000, num_chains=4, chain_method="parallel" ) mcmc = MCMC(**sample_kwargs) mcmc.run(random.PRNGKey(0), **data_dict)
az.summary(mcmc)
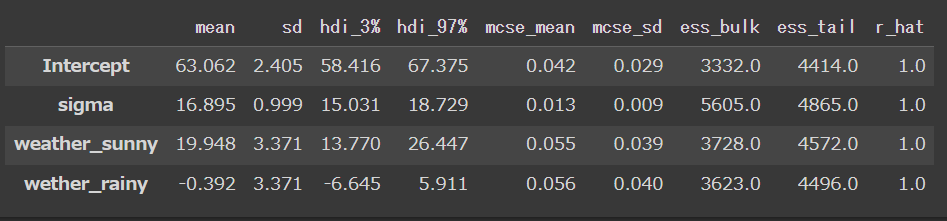
結果はこちらで、無事本紙と同様の値になりました。
モデルの確認
本紙ではbrms の marginal_effects によって各天気別の信用区間を表現していますが、
arvizには同様の機能はなさそうなので、
ここでは事後予測分布を生成し、各天気別の salesの予測区間を可視化してみます。
# 事後予測分布取得の準備 mcmc_samples=mcmc.get_samples() predictive = numpyro.infer.Predictive(model, mcmc_samples) # 予測用データの生成 rainy_pred = jnp.array([0,0,1]) sunny_pred = jnp.array([1,0,0]) # 事後予測分布の取得 ppc_samples = predictive(random.PRNGKey(0),N = 3,sales=None,rainy = rainy_pred,sunny = sunny_pred) idata_ppc = az.from_numpyro(mcmc, posterior_predictive=ppc_samples) sales_pred = idata_ppc.posterior_predictive['sales']
事後予測分布の取得過程は前回記事と全く同一です。
では、まず各天気別の予測分布の可視化です。
az.plot_posterior(sales_pred)
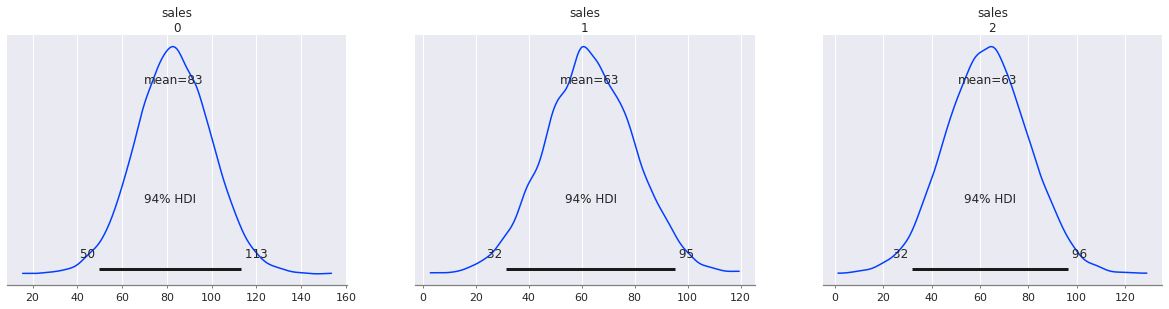
少し分かりづらいですが sales : 0 がsunny、 sales : 1 がcloudy、 sales : 2 がrainy の際の事後予測分布になります。
sunny の際に sales が最も高くなりそうなことがわかりました。
なお、少々分かりづらいので別の形でも確認。
az.plot_forest(sales_pred,combined=True)
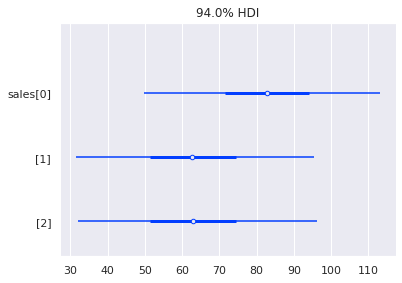
こちらのほうが、sunnyのときに sales が高くなる推定結果が明らかです。
おわりに
以上、カテゴリ変数による分散分析モデルの実装でした。
次回もこれまでとほとんど同様、正規線形モデルの実装です。